Voice Assistant
Chainlit let’s you access the user’s microphone audio stream and process it in real-time. This can be used to create voice assistants, transcribe audio, or even process audio in real-time.The user will only be able to use the microphone if you implemented the
@cl.on_audio_chunk decorator.
OpenAI Realtime
Cookbook example showcasing how to use Chainlit with realtime audio APIs.
Text To Speech -> Speech to Text
Cookbook example showcasing speech to text -> answer generation -> text to speech.
Spontaneous File Uploads
Within the Chainlit application, users have the flexibility to attach any file to their messages. This can be achieved either by utilizing the drag and drop feature or by clicking on theattach button located in the chat bar.
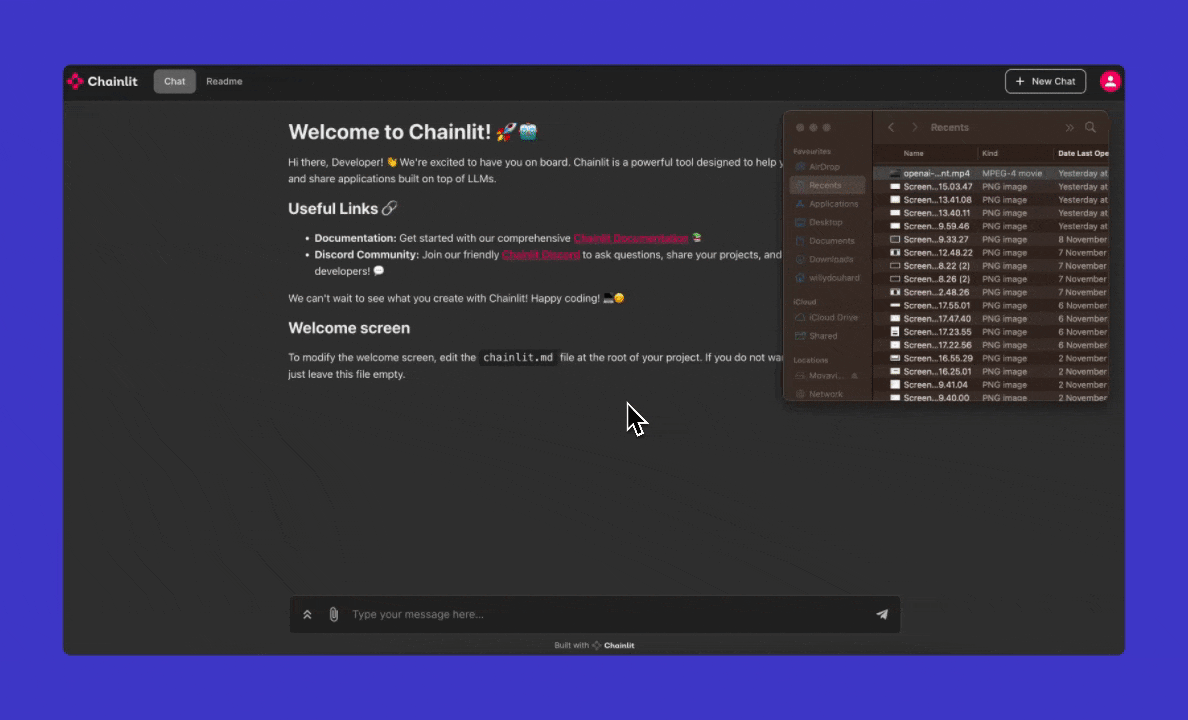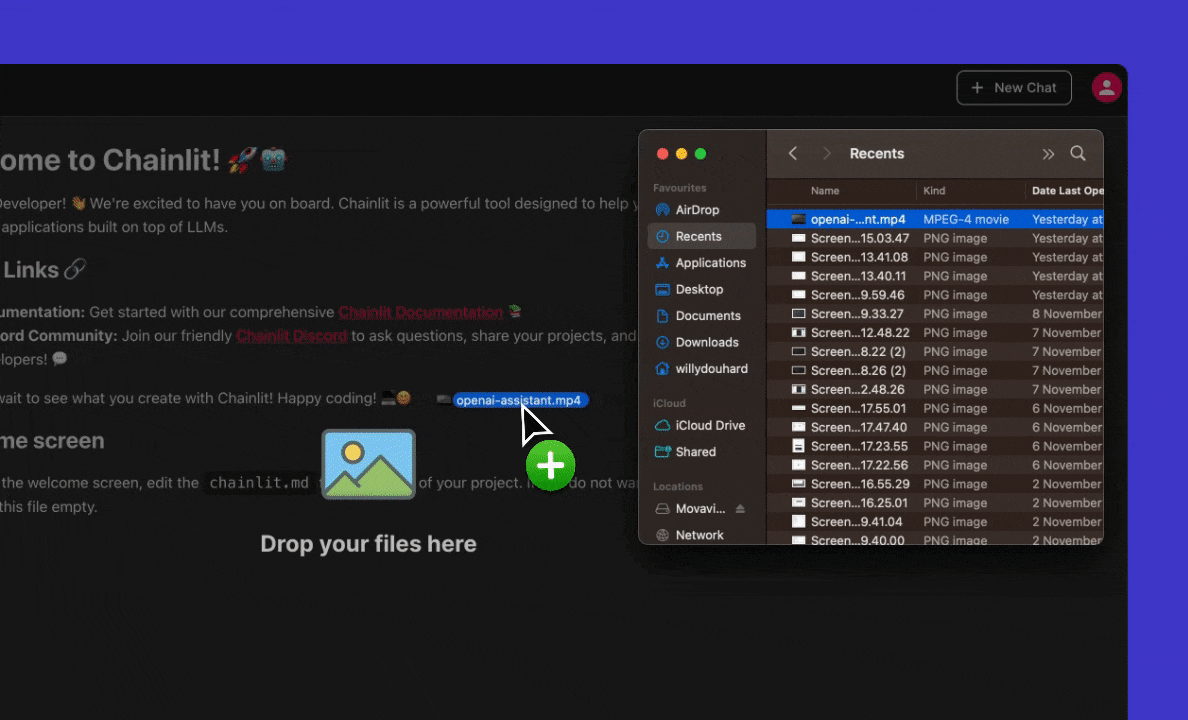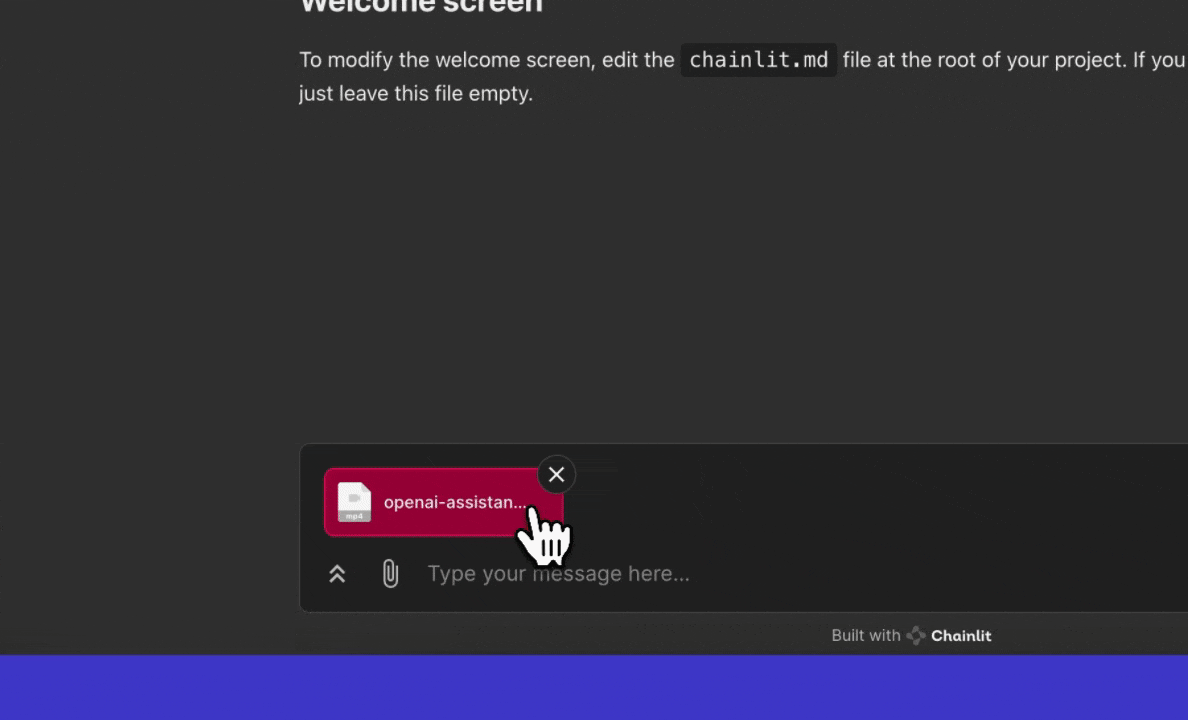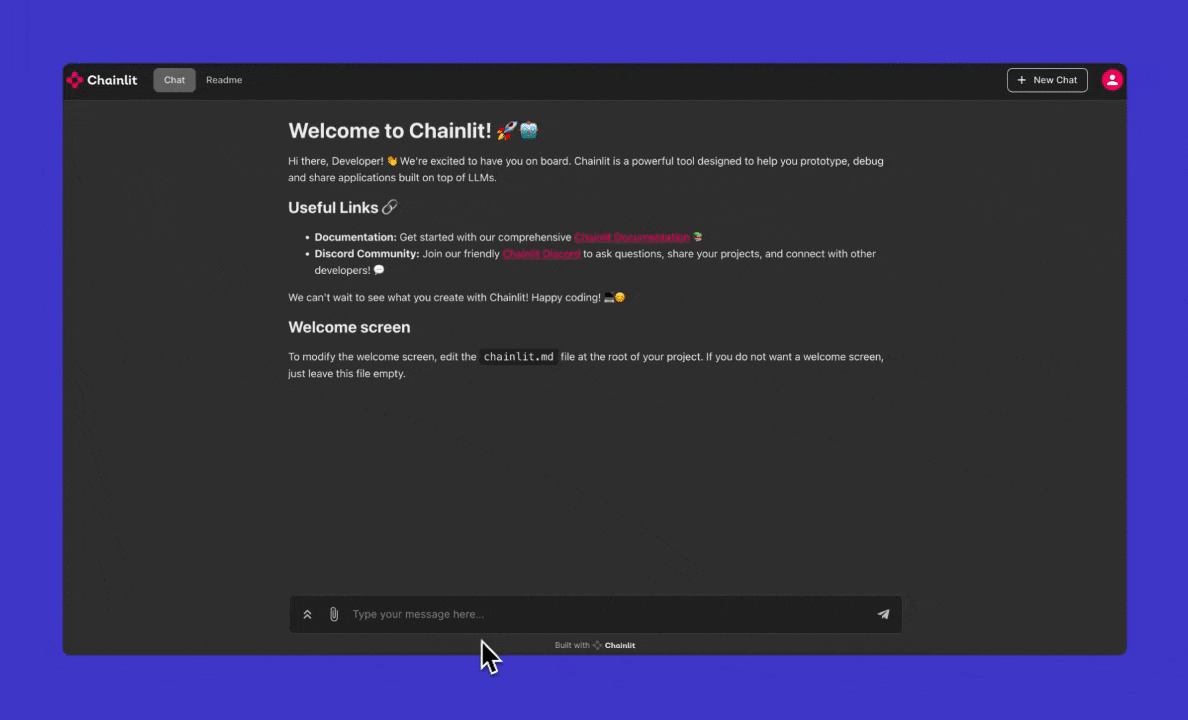
Disabling Spontaneous File Uploads
If you wish to disable this feature (which would prevent users from attaching files to their messages), you can do so by settingfeatures.spontaneous_file_upload.enabled=false in your Chainlit config file.