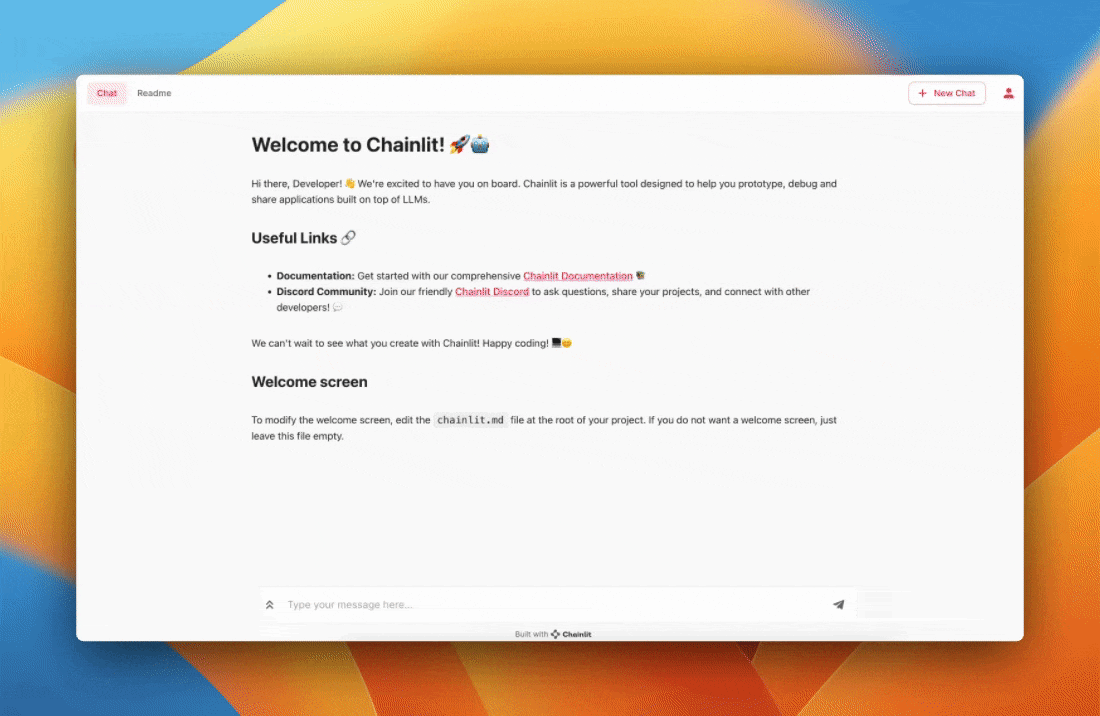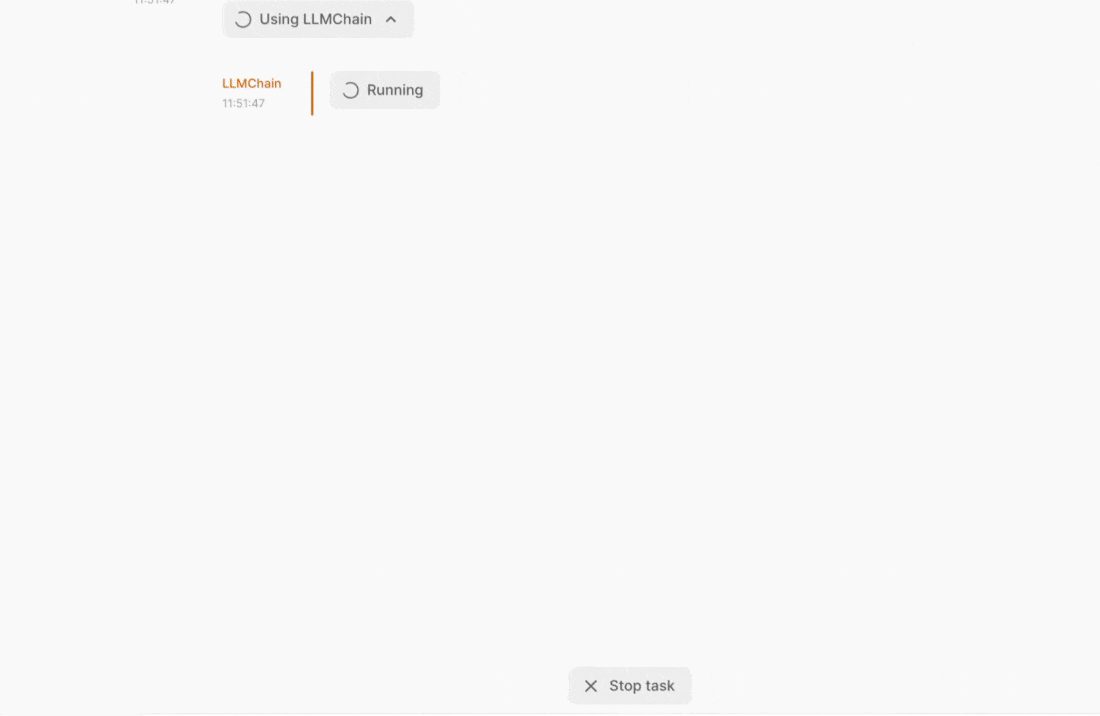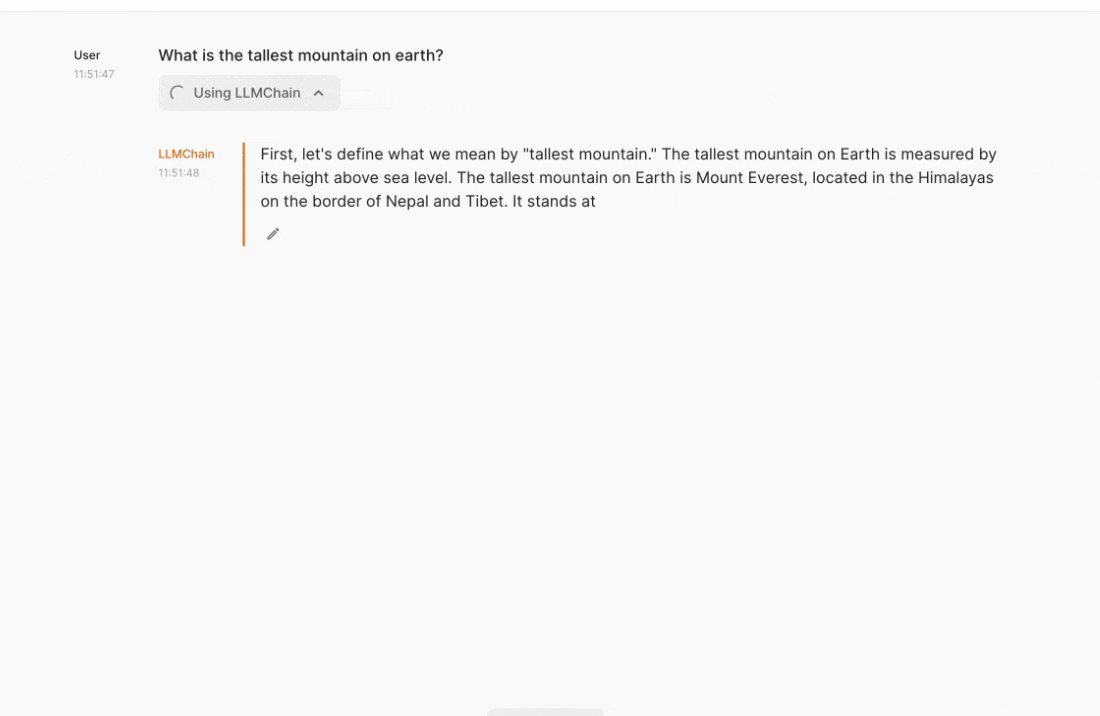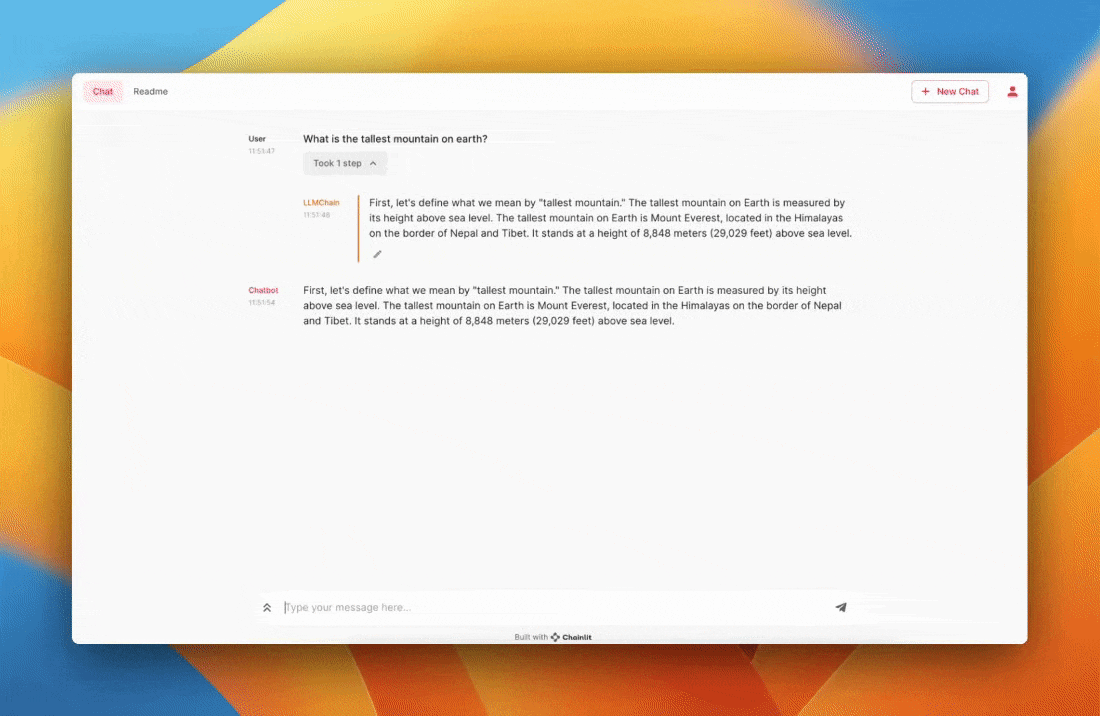
Preview of what you will build
Prerequisites
Before getting started, make sure you have the following:- A working installation of Chainlit
- The LangChain package installed
- An OpenAI API key
- Basic understanding of Python programming
Step 1: Create a Python file
Create a new Python file namedapp.py in your project directory. This file will contain the main logic for your LLM application.
Step 2: Write the Application Logic
Inapp.py, import the necessary packages and define one function to handle a new chat session and another function to handle messages incoming from the UI.
With LangChain
Let’s go through a small example.If your agent/chain does not have an async implementation, fallback to the
sync implementation.
Runnable with a custom ChatPromptTemplate for each chat session. The Runnable is invoked everytime a user sends a message to generate the response.
The callback handler is responsible for listening to the chain’s intermediate steps and sending them to the UI.
With LangGraph
Step 3: Run the Application
To start your app, open a terminal and navigate to the directory containingapp.py. Then run the following command:
-w flag tells Chainlit to enable auto-reloading, so you don’t need to restart the server every time you make changes to your application. Your chatbot UI should now be accessible at http://localhost:8000.