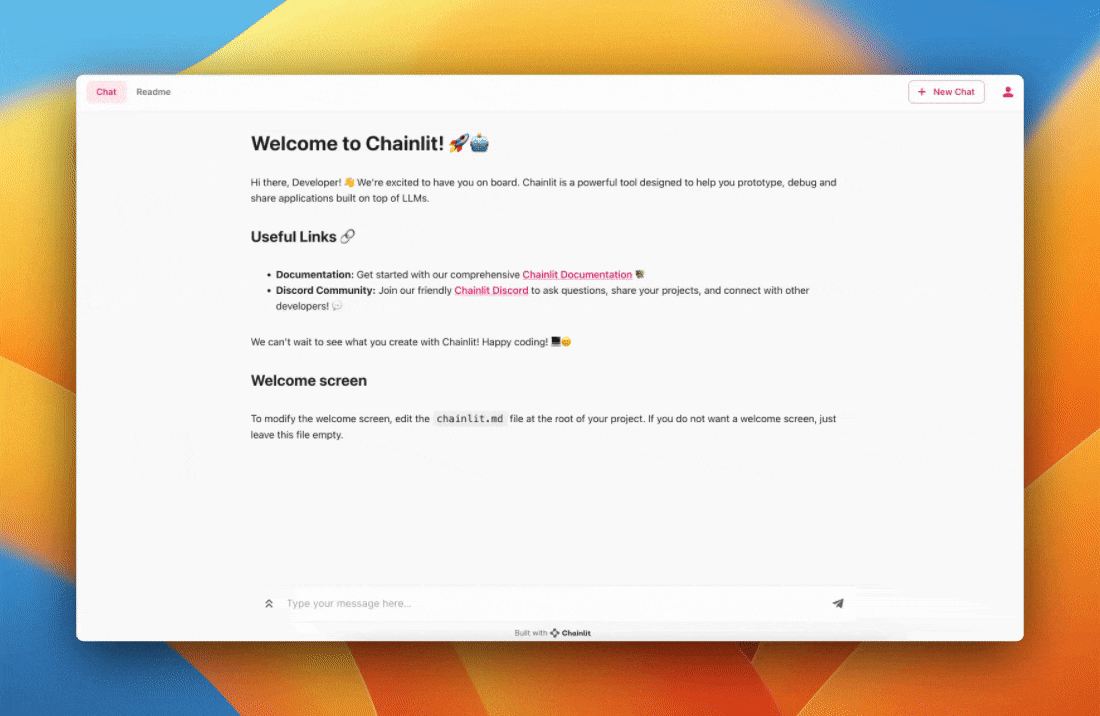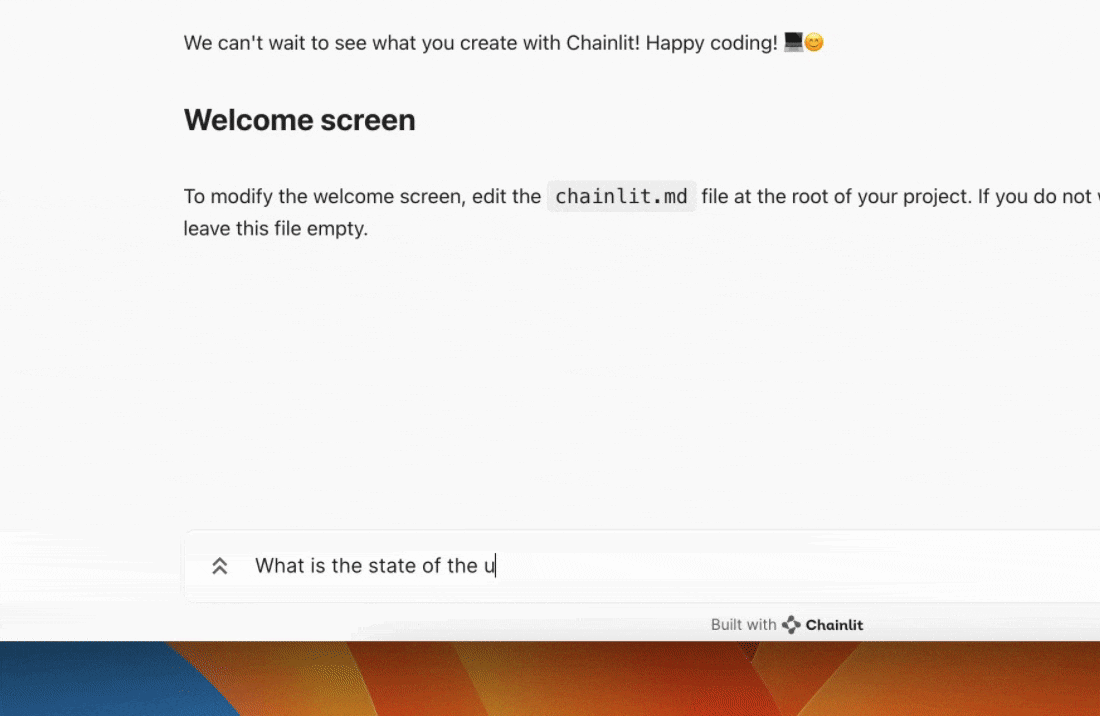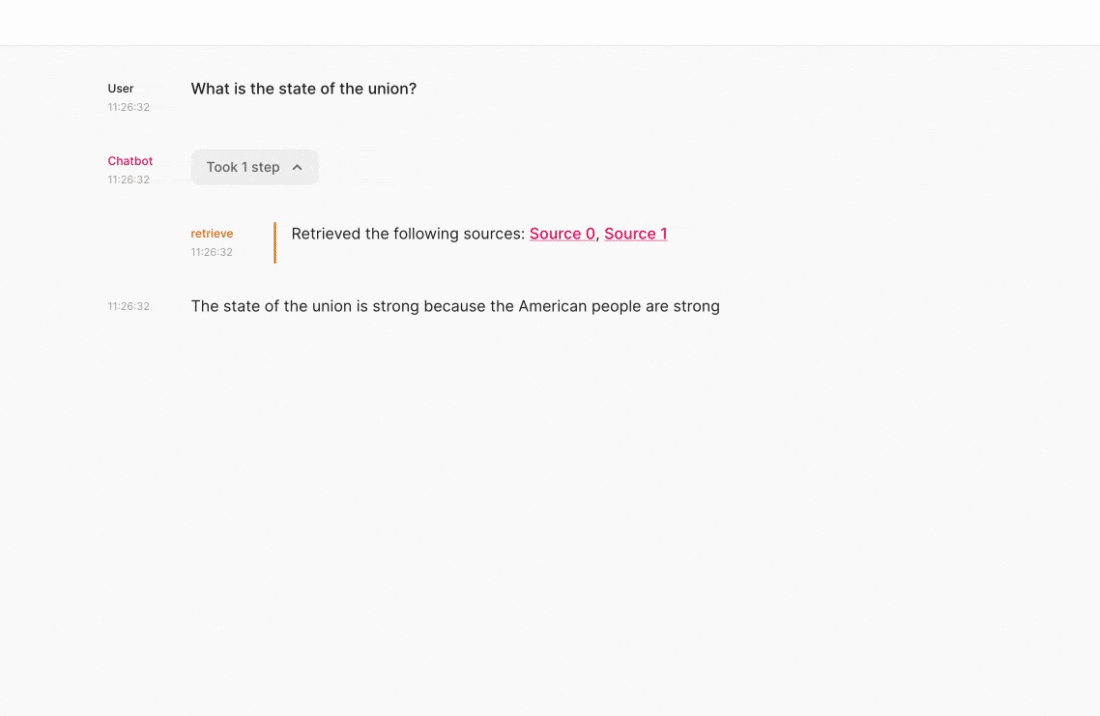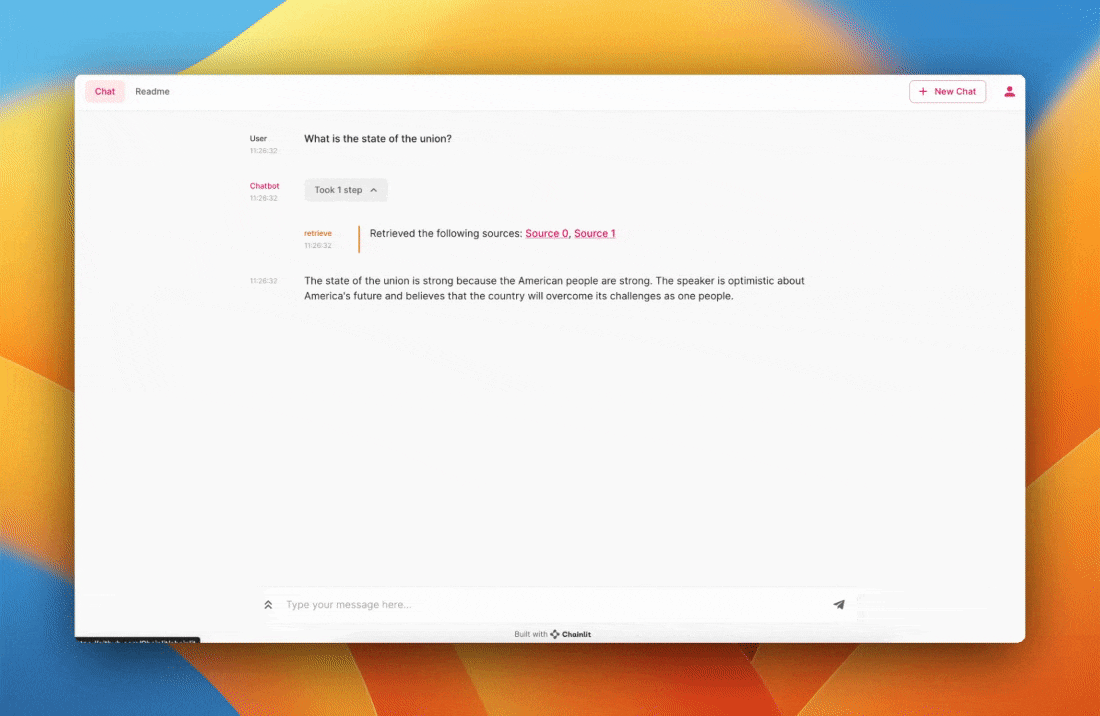
Preview of the app you'll build
Prerequisites
Before diving in, ensure that the following prerequisites are met:- A working installation of Chainlit
- The Llama Index package installed
- An OpenAI API key
- A basic understanding of Python programming
Step 1: Set Up Your Data Directory
Create a folder nameddata in the root of your app folder. Download the state of the union file (or any files of your own choice) and place it in the data folder.
Step 2: Create the Python Script
Create a new Python file namedapp.py in your project directory. This file will contain the main logic for your LLM application.
Step 3: Write the Application Logic
Inapp.py, import the necessary packages and define one function to handle a new chat session and another function to handle messages incoming from the UI.
In this tutorial, we are going to use RetrieverQueryEngine. Here’s the basic structure of the script:
app.py
RetrieverQueryEngine for each chat session. The RetrieverQueryEngine is invoked everytime a user sends a message to generate the response.
The callback handlers are responsible for listening to the intermediate steps and sending them to the UI.
Step 4: Launch the Application
To kick off your LLM app, open a terminal, navigate to the directory containingapp.py, and run the following command:
-w flag enables auto-reloading so that you don’t have to restart the server each time you modify your application. Your chatbot UI should now be accessible at http://localhost:8000.